Deepseek? It's Easy If you Happen to Do It Smart
페이지 정보
작성자 Christina 작성일25-03-01 17:22 조회2회 댓글0건관련링크
본문
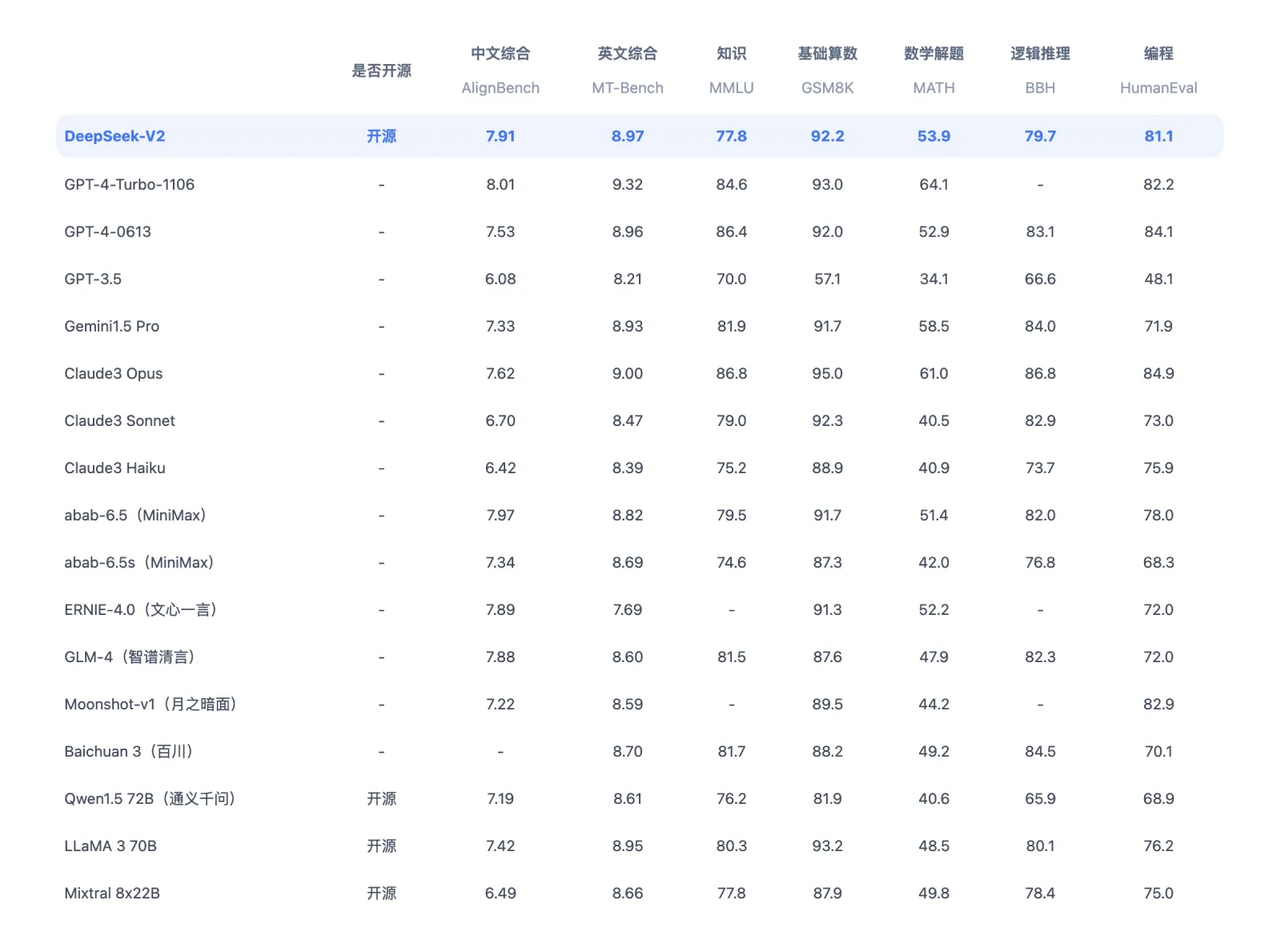 In 2023, High-Flyer launched DeepSeek as a separate venture solely centered on AI. Model Weights: Some models require separate weight downloads. Chinese startup DeepSeek lately took center stage in the tech world with its startlingly low utilization of compute resources for its superior AI mannequin known as R1, a model that's believed to be competitive with Open AI's o1 despite the company's claims that DeepSeek only value $6 million and 2,048 GPUs to practice. The fabled $6 million was just a portion of the total coaching value. However, this figure refers solely to a portion of the full coaching value- specifically, the GPU time required for pre-coaching. Specifically, we wanted to see if the size of the mannequin, i.e. the variety of parameters, impacted efficiency. It comprises 236B total parameters, of which 21B are activated for every token. In case you are in Reader mode please exit and log into your Times account, or subscribe for all the Times. 2.4 If you lose your account, neglect your password, or leak your verification code, you may observe the process to attraction for recovery in a timely manner. DeepSeek's rise underscores how a effectively-funded, unbiased AI firm can problem industry leaders.
In 2023, High-Flyer launched DeepSeek as a separate venture solely centered on AI. Model Weights: Some models require separate weight downloads. Chinese startup DeepSeek lately took center stage in the tech world with its startlingly low utilization of compute resources for its superior AI mannequin known as R1, a model that's believed to be competitive with Open AI's o1 despite the company's claims that DeepSeek only value $6 million and 2,048 GPUs to practice. The fabled $6 million was just a portion of the total coaching value. However, this figure refers solely to a portion of the full coaching value- specifically, the GPU time required for pre-coaching. Specifically, we wanted to see if the size of the mannequin, i.e. the variety of parameters, impacted efficiency. It comprises 236B total parameters, of which 21B are activated for every token. In case you are in Reader mode please exit and log into your Times account, or subscribe for all the Times. 2.4 If you lose your account, neglect your password, or leak your verification code, you may observe the process to attraction for recovery in a timely manner. DeepSeek's rise underscores how a effectively-funded, unbiased AI firm can problem industry leaders.
 The corporate has recently drawn consideration for its AI models that claim to rival trade leaders like OpenAI. This model, along with subsequent releases like DeepSeek-R1 in January 2025, has positioned DeepSeek as a key player in the worldwide AI landscape, difficult established tech giants and marking a notable second in AI growth. Chinese artificial intelligence lab DeepSeek roiled markets in January, setting off a large tech and semiconductor selloff after unveiling AI models that it stated have been cheaper and more efficient than American ones. First rule of tech when dealing with Chinese corporations. President Donald Trump described it as a "wake-up name" for US companies. This strategy has, for a lot of reasons, led some to consider that fast developments may reduce the demand for prime-finish GPUs, impacting corporations like Nvidia. DeepSeek-V3 works like the usual ChatGPT mannequin, providing fast responses, DeepSeek generating text, rewriting emails and summarizing paperwork. Benchmarks consistently show that DeepSeek-V3 outperforms GPT-4o, Claude 3.5, and Llama 3.1 in multi-step downside-fixing and contextual understanding. DeepSeek exclusively hires from within China, specializing in abilities and downside-fixing skills moderately than formal credentials, in line with SemiAnalysis. Then there's something that one would not count on from a Chinese firm: talent acquisition from mainland China, with no poaching from Taiwan or the U.S.
The corporate has recently drawn consideration for its AI models that claim to rival trade leaders like OpenAI. This model, along with subsequent releases like DeepSeek-R1 in January 2025, has positioned DeepSeek as a key player in the worldwide AI landscape, difficult established tech giants and marking a notable second in AI growth. Chinese artificial intelligence lab DeepSeek roiled markets in January, setting off a large tech and semiconductor selloff after unveiling AI models that it stated have been cheaper and more efficient than American ones. First rule of tech when dealing with Chinese corporations. President Donald Trump described it as a "wake-up name" for US companies. This strategy has, for a lot of reasons, led some to consider that fast developments may reduce the demand for prime-finish GPUs, impacting corporations like Nvidia. DeepSeek-V3 works like the usual ChatGPT mannequin, providing fast responses, DeepSeek generating text, rewriting emails and summarizing paperwork. Benchmarks consistently show that DeepSeek-V3 outperforms GPT-4o, Claude 3.5, and Llama 3.1 in multi-step downside-fixing and contextual understanding. DeepSeek exclusively hires from within China, specializing in abilities and downside-fixing skills moderately than formal credentials, in line with SemiAnalysis. Then there's something that one would not count on from a Chinese firm: talent acquisition from mainland China, with no poaching from Taiwan or the U.S.
Then DeepSeek shook the excessive-tech world with an Open AI-aggressive R1 AI model. Open your terminal and run the next command. A major differentiator for DeepSeek is its capability to run its personal information centers, in contrast to most other AI startups that depend on external cloud providers. The coverage continues: "Where we switch any private info out of the nation the place you reside, including for a number of of the purposes as set out on this Policy, we'll achieve this in accordance with the necessities of applicable information protection legal guidelines." The coverage does not mention GDPR compliance. DeepSeek took the eye of the AI world by storm when it disclosed the minuscule hardware necessities of its DeepSeek-V3 Mixture-of-Experts (MoE) AI model that are vastly lower when in comparison with those of U.S.-based mostly fashions. • Knowledge: (1) On academic benchmarks corresponding to MMLU, MMLU-Pro, and GPQA, DeepSeek-V3 outperforms all different open-source fashions, reaching 88.5 on MMLU, 75.9 on MMLU-Pro, and 59.1 on GPQA. On the factual knowledge benchmark, SimpleQA, DeepSeek-V3 falls behind GPT-4o and Claude-Sonnet, primarily on account of its design focus and useful resource allocation. Businesses might remain wary of adopting DeepSeek r1 due to these considerations, which may hinder its market progress and restrict US data publicity to China.
Due to the expertise inflow, DeepSeek has pioneered innovations like Multi-Head Latent Attention (MLA), which required months of growth and substantial GPU utilization, SemiAnalysis stories. Recruitment efforts target establishments like Peking University and Zhejiang University, providing highly competitive salaries. Its success challenges the dominance of US-based mostly AI fashions, signaling that rising players like DeepSeek may drive breakthroughs in areas that established companies have but to discover. AI companies is neither a good or a direct comparability. This is simply cope aiming to guard the inflated worth of "AI" firms. Its market value fell by $600bn on Monday. Now Monday morning will likely be a race to sell airline stocks and purchase some big inexperienced earlier than everybody else does. I think any large moves now is just unimaginable to get right. Get Tom's Hardware's greatest news and in-depth evaluations, straight to your inbox. I've tried constructing many brokers, Deepseek AI Online chat and actually, while it is simple to create them, it's an entirely totally different ball recreation to get them right. As Elon Musk noted a 12 months or so in the past, if you wish to be competitive in AI, you need to spend billions per 12 months, which is reportedly in the vary of what was spent.
If you have any kind of concerns relating to where and how you can utilize Deepseek AI Online chat, you could contact us at our site.
댓글목록
등록된 댓글이 없습니다.