Check out This Genius Deepseek Plan
페이지 정보
작성자 Ella 작성일25-03-17 08:22 조회2회 댓글0건관련링크
본문
 DeepSeek made it to number one within the App Store, merely highlighting how Claude, in contrast, hasn’t gotten any traction outdoors of San Francisco. Because of the poor efficiency at longer token lengths, here, we produced a brand new model of the dataset for every token size, by which we solely stored the functions with token size not less than half of the goal number of tokens. Increasing the number of epochs reveals promising potential for added performance good points whereas sustaining computational effectivity. So I spent some time researching present literature that could clarify the reasoning, and potential solutions to those problems. This shift is leveling the enjoying field, permitting smaller corporations and startups to build aggressive AI solutions without requiring in depth budgets. Companies can integrate it into their products without paying for usage, making it financially enticing. Indeed, you can very much make the case that the first end result of the chip ban is today’s crash in Nvidia’s stock worth. Reasoning models also improve the payoff for inference-solely chips which might be much more specialized than Nvidia’s GPUs. Again, although, while there are big loopholes in the chip ban, it seems prone to me that DeepSeek accomplished this with authorized chips. Third is the truth that DeepSeek pulled this off regardless of the chip ban.
DeepSeek made it to number one within the App Store, merely highlighting how Claude, in contrast, hasn’t gotten any traction outdoors of San Francisco. Because of the poor efficiency at longer token lengths, here, we produced a brand new model of the dataset for every token size, by which we solely stored the functions with token size not less than half of the goal number of tokens. Increasing the number of epochs reveals promising potential for added performance good points whereas sustaining computational effectivity. So I spent some time researching present literature that could clarify the reasoning, and potential solutions to those problems. This shift is leveling the enjoying field, permitting smaller corporations and startups to build aggressive AI solutions without requiring in depth budgets. Companies can integrate it into their products without paying for usage, making it financially enticing. Indeed, you can very much make the case that the first end result of the chip ban is today’s crash in Nvidia’s stock worth. Reasoning models also improve the payoff for inference-solely chips which might be much more specialized than Nvidia’s GPUs. Again, although, while there are big loopholes in the chip ban, it seems prone to me that DeepSeek accomplished this with authorized chips. Third is the truth that DeepSeek pulled this off regardless of the chip ban.
Despite the efficiency benefit of the FP8 format, sure operators still require a higher precision attributable to their sensitivity to low-precision computations. The model integrated superior mixture-of-experts architecture and FP8 mixed precision training, setting new benchmarks in language understanding and price-effective efficiency. I noted above that if DeepSeek had access to H100s they probably would have used a larger cluster to train their model, just because that may have been the easier option; the actual fact they didn’t, and have been bandwidth constrained, drove a whole lot of their decisions in terms of both mannequin architecture and their training infrastructure. I've been subbed to Claude Opus for a number of months (yes, I am an earlier believer than you people). Yes, this will likely help within the quick time period - again, DeepSeek would be even more practical with extra computing - but in the long run it simply sews the seeds for competition in an business - chips and semiconductor gear - over which the U.S. We imagine our release technique limits the preliminary set of organizations who might select to do that, and provides the AI group more time to have a discussion concerning the implications of such systems.
For years now we have now been subject to hand-wringing about the dangers of AI by the very same people dedicated to constructing it - and controlling it. But isn’t R1 now within the lead? Nvidia has a large lead when it comes to its means to combine multiple chips collectively into one giant virtual GPU. The easiest argument to make is that the significance of the chip ban has only been accentuated given the U.S.’s rapidly evaporating lead in software program. Software and knowhow can’t be embargoed - we’ve had these debates and realizations earlier than - but chips are physical objects and the U.S. This is also contrary to how most U.S. What issues me is the mindset undergirding something like the chip ban: as an alternative of competing via innovation in the future the U.S. Just look at the U.S. The API enterprise is doing higher, however API businesses basically are probably the most inclined to the commoditization trends that seem inevitable (and do notice that OpenAI and Anthropic’s inference costs look so much higher than DeepSeek as a result of they had been capturing plenty of margin; that’s going away). For instance, it is perhaps way more plausible to run inference on a standalone AMD GPU, utterly sidestepping AMD’s inferior chip-to-chip communications capability.
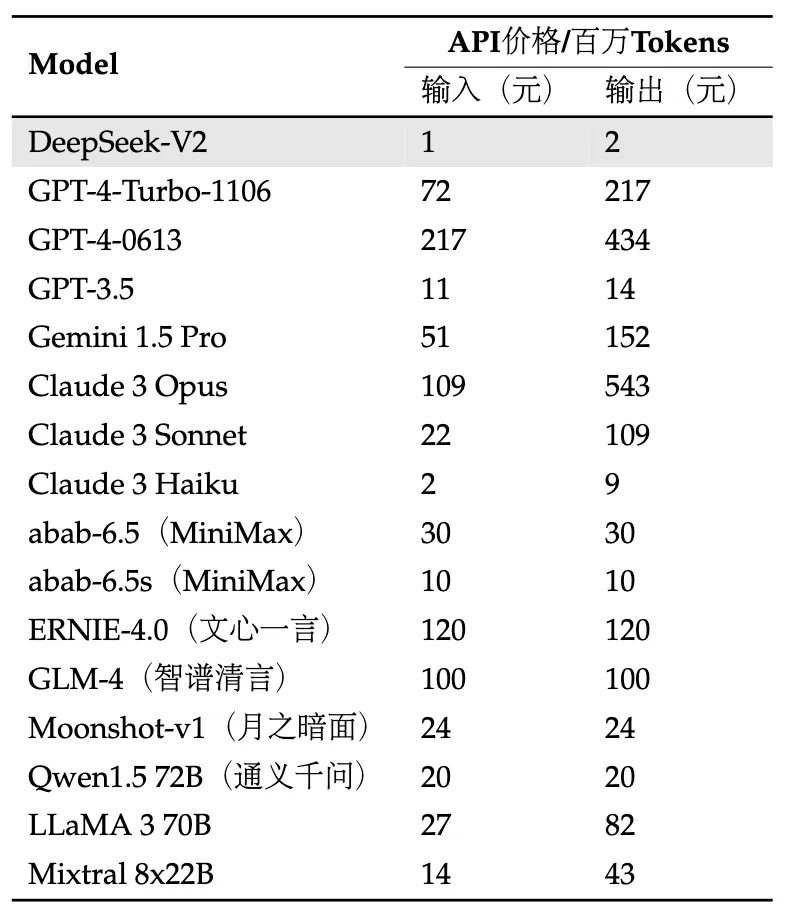 We additionally suppose governments should consider increasing or commencing initiatives to extra systematically monitor the societal impression and diffusion of AI technologies, and to measure the progression within the capabilities of such methods. I think it’s indicative that Deepseek v3 was allegedly skilled for less than $10m. I don’t assume so; this has been overstated. This flexible pricing construction makes DeepSeek an attractive possibility for both individual developers and large enterprises. The hype around Free DeepSeek Ai Chat is partly a mirrored image of the hype around AI. This part was a big shock for me as properly, to make certain, but the numbers are plausible. This is probably the largest thing I missed in my surprise over the reaction. 17%) drop of their inventory in response to this was baffling. DeepSeek, nonetheless, simply demonstrated that one other route is on the market: heavy optimization can produce remarkable results on weaker hardware and with lower memory bandwidth; simply paying Nvidia extra isn’t the only way to make higher fashions. We are aware that some researchers have the technical capability to reproduce and open supply our results. At the identical time, there should be some humility about the truth that earlier iterations of the chip ban appear to have immediately led to DeepSeek’s improvements.
We additionally suppose governments should consider increasing or commencing initiatives to extra systematically monitor the societal impression and diffusion of AI technologies, and to measure the progression within the capabilities of such methods. I think it’s indicative that Deepseek v3 was allegedly skilled for less than $10m. I don’t assume so; this has been overstated. This flexible pricing construction makes DeepSeek an attractive possibility for both individual developers and large enterprises. The hype around Free DeepSeek Ai Chat is partly a mirrored image of the hype around AI. This part was a big shock for me as properly, to make certain, but the numbers are plausible. This is probably the largest thing I missed in my surprise over the reaction. 17%) drop of their inventory in response to this was baffling. DeepSeek, nonetheless, simply demonstrated that one other route is on the market: heavy optimization can produce remarkable results on weaker hardware and with lower memory bandwidth; simply paying Nvidia extra isn’t the only way to make higher fashions. We are aware that some researchers have the technical capability to reproduce and open supply our results. At the identical time, there should be some humility about the truth that earlier iterations of the chip ban appear to have immediately led to DeepSeek’s improvements.
댓글목록
등록된 댓글이 없습니다.