The right way to Get (A) Fabulous Deepseek Ai News On A Tight Budget
페이지 정보
작성자 Clifton 작성일25-02-16 13:42 조회68회 댓글0건관련링크
본문
While many U.S. and Chinese AI firms chase market-pushed functions, DeepSeek’s researchers concentrate on foundational bottlenecks: improving coaching effectivity, lowering computational prices and enhancing model generalization. DeepSeek achieved environment friendly coaching with significantly much less assets in comparison with other AI fashions by utilizing a "Mixture of Experts" architecture, where specialised sub-fashions handle totally different tasks, successfully distributing computational load and only activating related parts of the model for each input, thus lowering the need for large amounts of computing power and information. Well, it isn't an amazing day for AI investors, and NVIDIA in particular, for the reason that Chinese agency DeepSeek has managed to disrupt trade norms with its newest R1 AI model, which is alleged to change the idea of mannequin training and the resources concerned behind it. DeepSeek’s breakthroughs have been in attaining higher efficiency: getting good outcomes with fewer sources. Founded in 2023, DeepSeek has achieved its results with a fraction of the cash and computing energy of its rivals.
US officials claimed the app is a supposed "national security" threat - their favourite excuse to justify imposing restrictions on Silicon Valley’s Chinese competitors. The startup's chatbot surged to grow to be probably the most downloaded free app on Apple's U.S. DeepSeek says its model was developed with present technology together with open source software that can be used and shared by anyone without spending a dime. Practical common expression matching free of scalability and performance obstacles. Typically, when a big language mannequin (LLM) is trained to not answer queries, it will usually reply that it's incapable of fulfilling the request. In a weblog post, AI model testing firm Promptfoo mentioned, "Today we're publishing a dataset of prompts covering delicate topics which can be likely to be censored by the CCP. Data privacy emerges as one other critical challenge; the processing of huge person-generated data raises potential publicity to breaches, misuse or unintended leakage, even with anonymization measures, risking the compromise of sensitive info. However, the projected growth of energy consumption for storage and memory in these projections, is far lower than that required for GPU processing for AI fashions. But WIRED stories that for years, DeepSeek founder Liang Wenfung's hedge fund High-Flyer has been stockpiling the chips that form the backbone of AI - generally known as GPUs, or graphics processing items.
 While most LLMs treat ethics as a reactive checkbox, DeepSeek r1 bakes it into every response. But whereas the current iteration of The AI Scientist demonstrates a strong potential to innovate on high of effectively-established ideas, resembling Diffusion Modeling or Transformers, it remains to be an open question whether or not such methods can ultimately suggest genuinely paradigm-shifting concepts. Open the Applications folder, find Ollama, and double-click to launch it. Our group is about connecting folks by open and considerate conversations. Deepseek’s environment friendly AI training has precipitated much dialogue in the AI neighborhood and precipitated volatility in AI related stocks. Thanks for reading our neighborhood guidelines. Sep 16 2023 LLM Apps: Don't get Stuck in an Infinite Loop! A year that began with OpenAI dominance is now ending with Anthropic’s Claude being my used LLM and the introduction of a number of labs which can be all attempting to push the frontier from xAI to Chinese labs like DeepSeek and Qwen. Why this matters - intelligence is the very best defense: Research like this both highlights the fragility of LLM expertise as well as illustrating how as you scale up LLMs they appear to grow to be cognitively succesful sufficient to have their own defenses towards weird attacks like this.
While most LLMs treat ethics as a reactive checkbox, DeepSeek r1 bakes it into every response. But whereas the current iteration of The AI Scientist demonstrates a strong potential to innovate on high of effectively-established ideas, resembling Diffusion Modeling or Transformers, it remains to be an open question whether or not such methods can ultimately suggest genuinely paradigm-shifting concepts. Open the Applications folder, find Ollama, and double-click to launch it. Our group is about connecting folks by open and considerate conversations. Deepseek’s environment friendly AI training has precipitated much dialogue in the AI neighborhood and precipitated volatility in AI related stocks. Thanks for reading our neighborhood guidelines. Sep 16 2023 LLM Apps: Don't get Stuck in an Infinite Loop! A year that began with OpenAI dominance is now ending with Anthropic’s Claude being my used LLM and the introduction of a number of labs which can be all attempting to push the frontier from xAI to Chinese labs like DeepSeek and Qwen. Why this matters - intelligence is the very best defense: Research like this both highlights the fragility of LLM expertise as well as illustrating how as you scale up LLMs they appear to grow to be cognitively succesful sufficient to have their own defenses towards weird attacks like this.
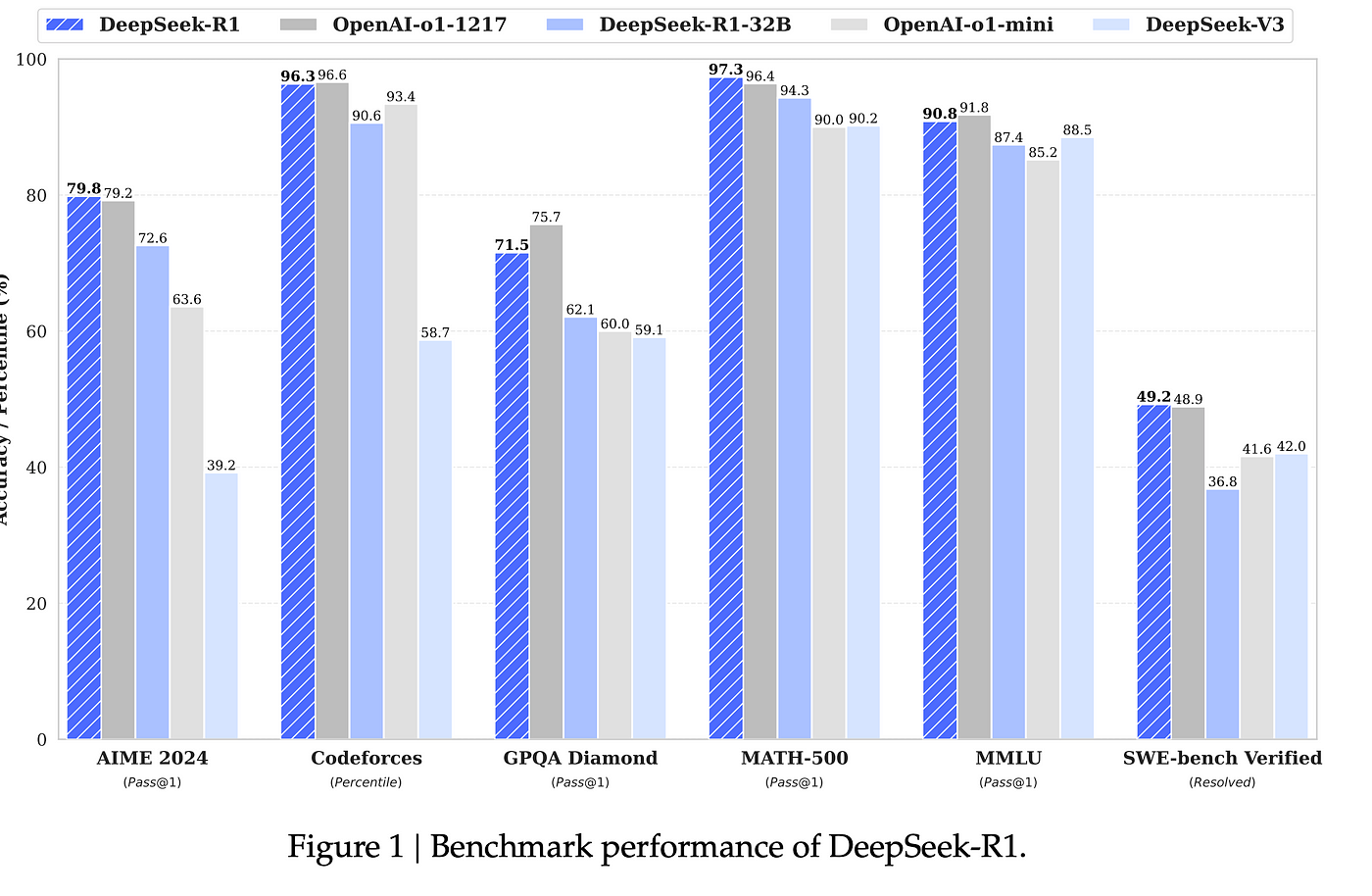
However, we should not be surprised at advances like those made in growing Deepseek. However, these were not the type of refusals expected from a reasoning-targeted AI model. Gadgets 360 staff members examined these prompts on DeepSeek and confronted related refusals. LLaMa-10, driving a big conversation within the civilian theatre about how the system had a high variety of refusals in some areas resulting from ‘woke’ security training and that this had additionally led to the era of ‘nonsense science’ as a direct casualty of ‘DEI safetyism’. You possibly can limit the conversation context to an Org heading with `gptel-org-set-subject'. This may be in comparison with the estimated 5.8GW of energy consumed by San Francisco, CA. In different phrases, single information centers are projected to require as a lot energy as a large city. Maybe it does not take a lot capital, compute, and power in any case. And once more as I discussed, we're far more laissez faire. The DeepSeek models’ glorious efficiency, which rivals those of one of the best closed LLMs from OpenAI and Anthropic, spurred a stock-market route on 27 January that wiped off more than US $600 billion from main AI stocks.
댓글목록
등록된 댓글이 없습니다.