The Secret History Of Deepseek
페이지 정보
작성자 Chris 작성일25-03-06 10:47 조회2회 댓글0건관련링크
본문
"Unlike many Chinese AI firms that rely closely on entry to superior hardware, DeepSeek has focused on maximizing software program-driven resource optimization," explains Marina Zhang, an affiliate professor on the University of Technology Sydney, who studies Chinese improvements. DeepSeek’s willingness to share these innovations with the general public has earned it appreciable goodwill inside the global AI research community. Update-Jan. 27, 2025: Free DeepSeek Online This article has been up to date since it was first revealed to incorporate additional data and reflect more moderen share worth values. For many Chinese AI firms, developing open source fashions is the only strategy to play catch-up with their Western counterparts, as a result of it attracts extra customers and contributors, which in turn assist the fashions grow. It’s a starkly totally different manner of operating from established web corporations in China, the place teams are sometimes competing for sources. But with its latest launch, DeepSeek proves that there’s one other approach to win: by revamping the foundational structure of AI fashions and using limited assets extra efficiently. "Our core technical positions are principally filled by people who graduated this year or previously one or two years," Liang informed 36Kr in 2023. The hiring technique helped create a collaborative firm culture the place folks have been free to make use of ample computing sources to pursue unorthodox analysis tasks.
DeepSeek has additionally made important progress on Multi-head Latent Attention (MLA) and Mixture-of-Experts, two technical designs that make DeepSeek models more price-efficient by requiring fewer computing sources to prepare. Then, in 2023, Liang, who has a master's degree in laptop science, determined to pour the fund’s assets into a brand new company referred to as DeepSeek that may construct its own cutting-edge models-and hopefully develop synthetic normal intelligence. Sufficient GPU assets in your workload. Companies like DeepSeek need tens of thousands of Nvidia Hopper GPUs (H100, H20, H800) to practice its massive-language models. I want you to use market evaluation and competitor information to establish a dynamic and aggressive pricing strategy. In this stage, Deepseek AI Online chat about 70% of the info comes from vision-language sources, and the remaining 30% is textual content-only knowledge sourced from the LLM pre training corpus. You will need to stress that we have no idea for positive if Anna’s Archive was used in the training of the LLM or the reasoning fashions, or what significance do these libraries have on the general training corpus. By providing a high-level overview of the venture necessities, DeepSeek V3 can counsel applicable data models, system components, and communication protocols. For years, High-Flyer had been stockpiling GPUs and constructing Fire-Flyer supercomputers to research monetary data.
As a result, most Chinese corporations have focused on downstream purposes moderately than building their very own fashions. Models converge to the same levels of efficiency judging by their evals. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to main closed-supply models. DeepSeek-AI (2024a) DeepSeek-AI. Deepseek-coder-v2: Breaking the barrier of closed-source models in code intelligence. By customizing fashions primarily based on area-specific knowledge and desired outcomes, you possibly can significantly improve the quality and relevance of AI-generated responses. For example, in healthcare settings the place fast entry to affected person data can save lives or enhance therapy outcomes, professionals benefit immensely from the swift search capabilities supplied by DeepSeek. "They optimized their model architecture utilizing a battery of engineering tips-customized communication schemes between chips, decreasing the dimensions of fields to save memory, and progressive use of the combo-of-models approach," says Wendy Chang, a software program engineer turned coverage analyst on the Mercator Institute for China Studies. We’ll spend a fair amount of time digging into "Group Relative Policy Optimization", which DeepSeek makes use of to elevate it’s reasoning skill, and is largely the source of it’s heightened performance over different open source fashions.
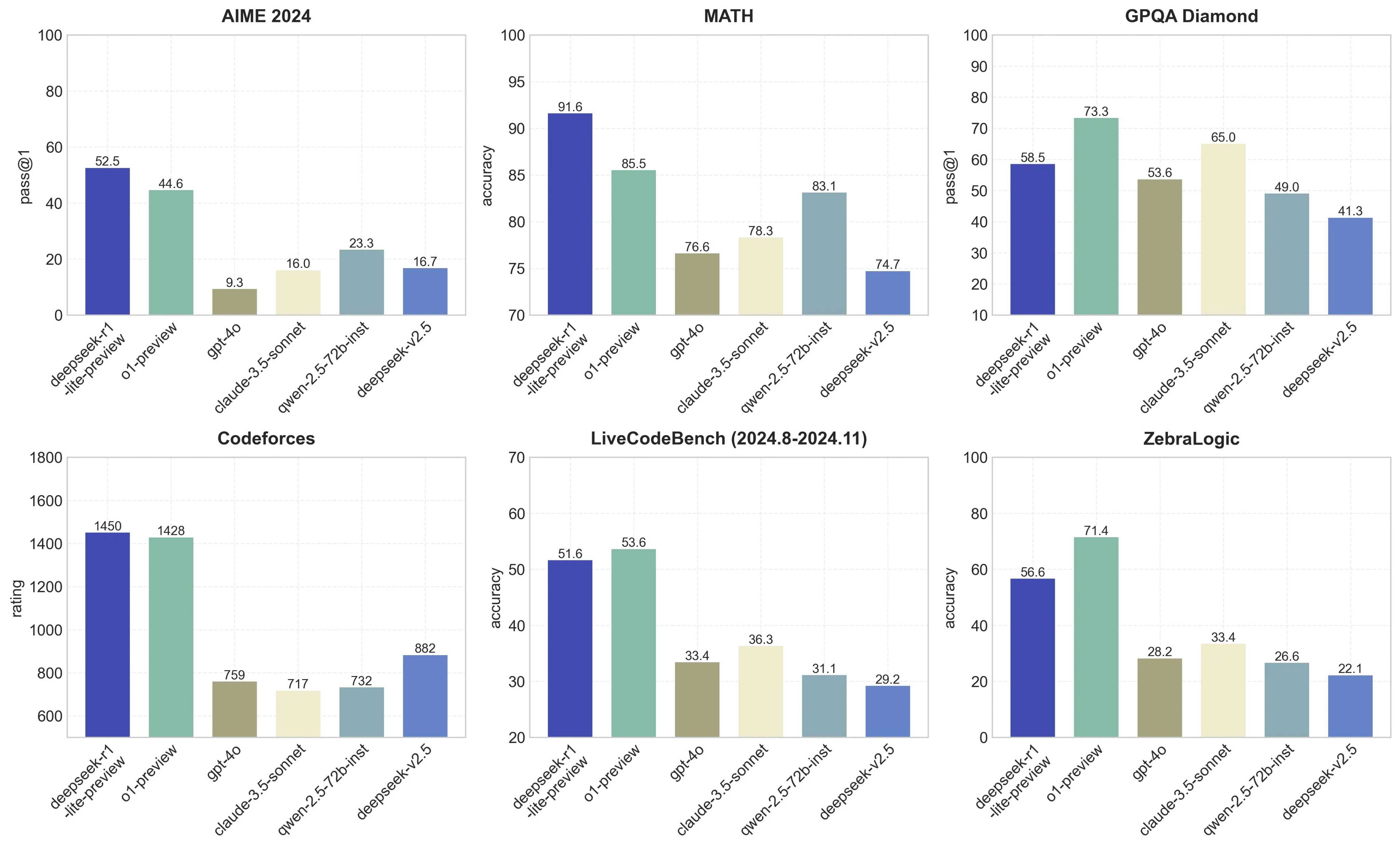 DeepSeek makes use of a refined system of this general approach to create fashions with heightened reasoning skills, which we’ll discover in depth. DeepSeek has claimed it is as powerful as ChatGPT’s o1 model in tasks like arithmetic and coding, however uses less reminiscence, slicing costs. DeepSeek at this time launched a brand new giant language model family, the R1 series, that’s optimized for reasoning tasks. To comply with our authorized obligations, or as necessary to perform tasks in the general public interest, or to guard the very important pursuits of our customers and other people. "Nvidia’s growth expectations had been undoubtedly a bit of ‘optimistic’ so I see this as a obligatory response," says Naveen Rao, Databricks VP of AI. In the early days, site visitors would simply be sent on to international nations and we are able to see in the info beneath some IP endpoints geo-location in China. DeepSeek didn't respond to several inquiries sent by WIRED. DeepSeek R1 and Cline aren’t just instruments-they’re a paradigm shift. "What’s much more alarming is that these aren’t novel ‘zero-day’ jailbreaks-many have been publicly identified for years," he says, claiming he noticed the mannequin go into extra depth with some instructions around psychedelics than he had seen another mannequin create. This is all great to listen to, although that doesn’t mean the large corporations out there aren’t massively rising their datacenter funding within the meantime.
DeepSeek makes use of a refined system of this general approach to create fashions with heightened reasoning skills, which we’ll discover in depth. DeepSeek has claimed it is as powerful as ChatGPT’s o1 model in tasks like arithmetic and coding, however uses less reminiscence, slicing costs. DeepSeek at this time launched a brand new giant language model family, the R1 series, that’s optimized for reasoning tasks. To comply with our authorized obligations, or as necessary to perform tasks in the general public interest, or to guard the very important pursuits of our customers and other people. "Nvidia’s growth expectations had been undoubtedly a bit of ‘optimistic’ so I see this as a obligatory response," says Naveen Rao, Databricks VP of AI. In the early days, site visitors would simply be sent on to international nations and we are able to see in the info beneath some IP endpoints geo-location in China. DeepSeek didn't respond to several inquiries sent by WIRED. DeepSeek R1 and Cline aren’t just instruments-they’re a paradigm shift. "What’s much more alarming is that these aren’t novel ‘zero-day’ jailbreaks-many have been publicly identified for years," he says, claiming he noticed the mannequin go into extra depth with some instructions around psychedelics than he had seen another mannequin create. This is all great to listen to, although that doesn’t mean the large corporations out there aren’t massively rising their datacenter funding within the meantime.
If you are you looking for more information about DeepSeek Chat take a look at our own web-page.
댓글목록
등록된 댓글이 없습니다.