How does DeepSeek aI Detector Work?
페이지 정보
작성자 Augustina 작성일25-03-06 21:59 조회3회 댓글0건관련링크
본문
 DeepSeek models which have been uncensored additionally display bias towards Chinese authorities viewpoints on controversial topics such as Xi Jinping's human rights file and Taiwan's political standing. DeepSeek's aggressive efficiency at relatively minimal cost has been acknowledged as probably difficult the worldwide dominance of American AI models. This means the model can have more parameters than it activates for each specific token, in a sense decoupling how a lot the model knows from the arithmetic price of processing particular person tokens. If e.g. each subsequent token gives us a 15% relative discount in acceptance, it may be attainable to squeeze out some more acquire from this speculative decoding setup by predicting a number of extra tokens out. The know-how has many skeptics and opponents, however its advocates promise a shiny future: AI will advance the global economy into a brand new era, they argue, making work extra efficient and opening up new capabilities throughout a number of industries that may pave the way for brand new research and developments. Meta spent constructing its newest AI know-how. The Chinese startup, DeepSeek, unveiled a brand new AI model last week that the company says is significantly cheaper to run than high options from main US tech firms like OpenAI, Google, and Meta.
DeepSeek models which have been uncensored additionally display bias towards Chinese authorities viewpoints on controversial topics such as Xi Jinping's human rights file and Taiwan's political standing. DeepSeek's aggressive efficiency at relatively minimal cost has been acknowledged as probably difficult the worldwide dominance of American AI models. This means the model can have more parameters than it activates for each specific token, in a sense decoupling how a lot the model knows from the arithmetic price of processing particular person tokens. If e.g. each subsequent token gives us a 15% relative discount in acceptance, it may be attainable to squeeze out some more acquire from this speculative decoding setup by predicting a number of extra tokens out. The know-how has many skeptics and opponents, however its advocates promise a shiny future: AI will advance the global economy into a brand new era, they argue, making work extra efficient and opening up new capabilities throughout a number of industries that may pave the way for brand new research and developments. Meta spent constructing its newest AI know-how. The Chinese startup, DeepSeek, unveiled a brand new AI model last week that the company says is significantly cheaper to run than high options from main US tech firms like OpenAI, Google, and Meta.
 Instead, they appear to be they had been rigorously devised by researchers who understood how a Transformer works and how its varied architectural deficiencies will be addressed. Multi-head latent attention relies on the intelligent remark that this is definitely not true, as a result of we can merge the matrix multiplications that might compute the upscaled key and worth vectors from their latents with the query and submit-attention projections, respectively. The key commentary right here is that "routing collapse" is an extreme scenario where the chance of every particular person knowledgeable being chosen is both 1 or 0. Naive load balancing addresses this by attempting to push the distribution to be uniform, i.e. every professional ought to have the same likelihood of being chosen. While we can not force anybody to do anything, and everyone seems to be Free DeepSeek v3 to make the selections they deem appropriate for his or her business, if we're not making use of AI in our store, we are doubtless being neglected of the future of e-commerce. The technical report notes this achieves higher performance than counting on an auxiliary loss whereas still ensuring applicable load stability.
Instead, they appear to be they had been rigorously devised by researchers who understood how a Transformer works and how its varied architectural deficiencies will be addressed. Multi-head latent attention relies on the intelligent remark that this is definitely not true, as a result of we can merge the matrix multiplications that might compute the upscaled key and worth vectors from their latents with the query and submit-attention projections, respectively. The key commentary right here is that "routing collapse" is an extreme scenario where the chance of every particular person knowledgeable being chosen is both 1 or 0. Naive load balancing addresses this by attempting to push the distribution to be uniform, i.e. every professional ought to have the same likelihood of being chosen. While we can not force anybody to do anything, and everyone seems to be Free DeepSeek v3 to make the selections they deem appropriate for his or her business, if we're not making use of AI in our store, we are doubtless being neglected of the future of e-commerce. The technical report notes this achieves higher performance than counting on an auxiliary loss whereas still ensuring applicable load stability.
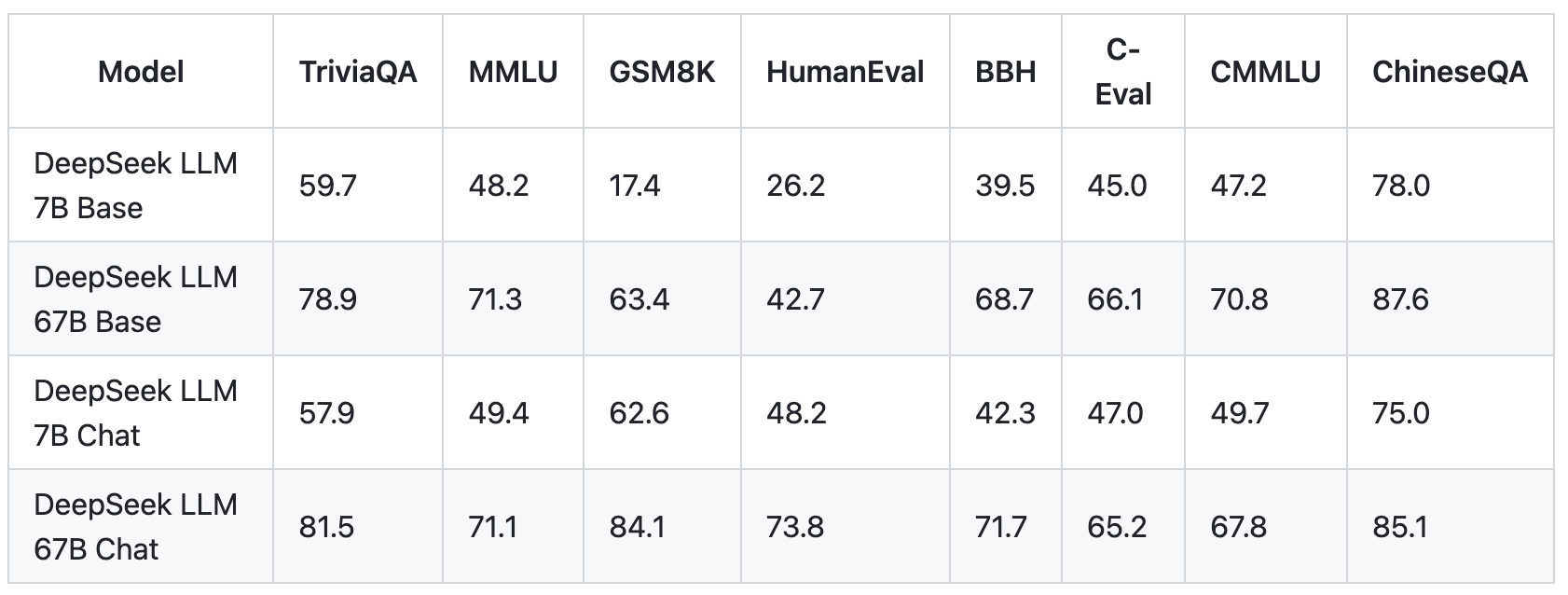
To see why, consider that any large language mannequin possible has a small quantity of information that it uses rather a lot, while it has too much of information that it makes use of relatively infrequently. This was adopted by DeepSeek LLM, a 67B parameter model aimed toward competing with different giant language models. A well-liked technique for avoiding routing collapse is to pressure "balanced routing", i.e. the property that every expert is activated roughly an equal variety of times over a sufficiently giant batch, by including to the coaching loss a term measuring how imbalanced the skilled routing was in a particular batch. However, if we don’t drive balanced routing, we face the risk of routing collapse. Shared experts are all the time routed to it doesn't matter what: they're excluded from both professional affinity calculations and any doable routing imbalance loss time period. Many consultants worry that the federal government of China may use the AI system for overseas influence operations, spreading disinformation, surveillance and the event of cyberweapons. This causes gradient descent optimization methods to behave poorly in MoE training, typically leading to "routing collapse", where the model gets stuck at all times activating the same few experts for each token as an alternative of spreading its knowledge and computation round the entire accessible experts.
To flee this dilemma, DeepSeek separates consultants into two types: shared specialists and routed consultants. KL divergence is a standard "unit of distance" between two probabilistic distributions. Whether you’re searching for a quick abstract of an article, assist with writing, or code debugging, the app works by using advanced AI models to ship relevant ends in real time. This can be a cry for assist. Once you see the method, it’s immediately obvious that it can't be any worse than grouped-query attention and it’s also prone to be considerably better. Methods comparable to grouped-question consideration exploit the possibility of the identical overlap, but they achieve this ineffectively by forcing attention heads which might be grouped together to all reply similarly to queries. Exploiting the fact that different heads want access to the same information is crucial for the mechanism of multi-head latent consideration. If we used low-rank compression on the key and worth vectors of particular person heads as an alternative of all keys and values of all heads stacked collectively, the tactic would merely be equal to utilizing a smaller head dimension to start with and we might get no acquire. This training was performed utilizing Supervised Fine-Tuning (SFT) and Reinforcement Learning. This not solely gives them a further goal to get sign from during training but additionally permits the mannequin to be used to speculatively decode itself.
댓글목록
등록된 댓글이 없습니다.